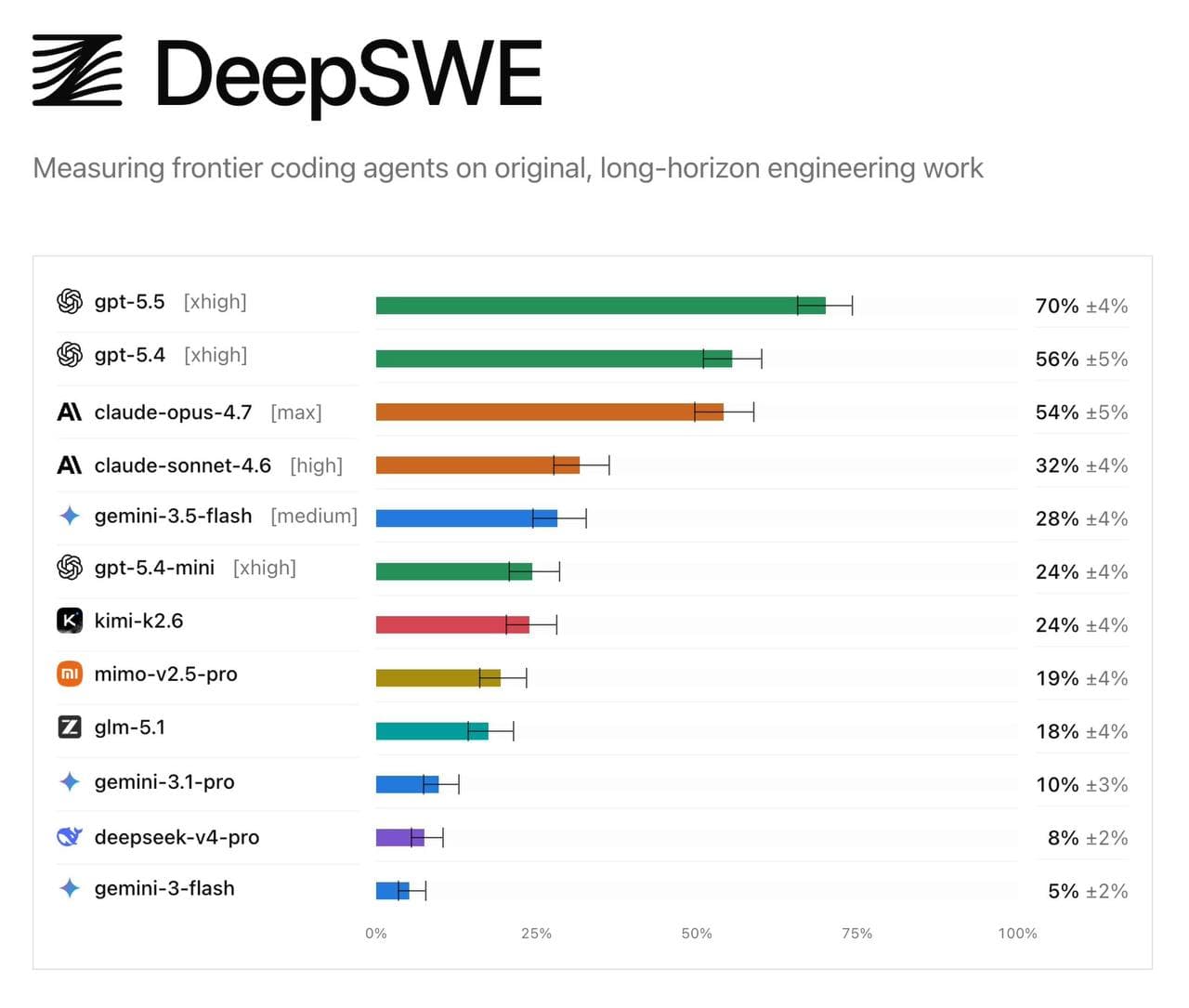
🤔 Looking at the results of the new agentic coding benchmark DeepSWE, it becomes clear that the whole story around Anthropic Mythos turned out to be just marketing.
If Mythos were truly an order of magnitude stronger than public models, Anthropic would have already released it to prevent the market from going back to OpenAI. GPT-5.5 scores 70%, GPT-5.4 - 56%, Claude Opus 4.7 at max - only 54%. This means the current flagship of Anthropic loses even to the previous iteration of OpenAI, and Sonnet 4.6 drops to 32%.
Coding is the most monetizable segment of the current AI industry, and Anthropic is losing ground here. Keeping "we have a cooler model inside" makes sense only until a public competitor starts to really eat into revenue. If Mythos existed in the form it was talked about, it would have already been shown.