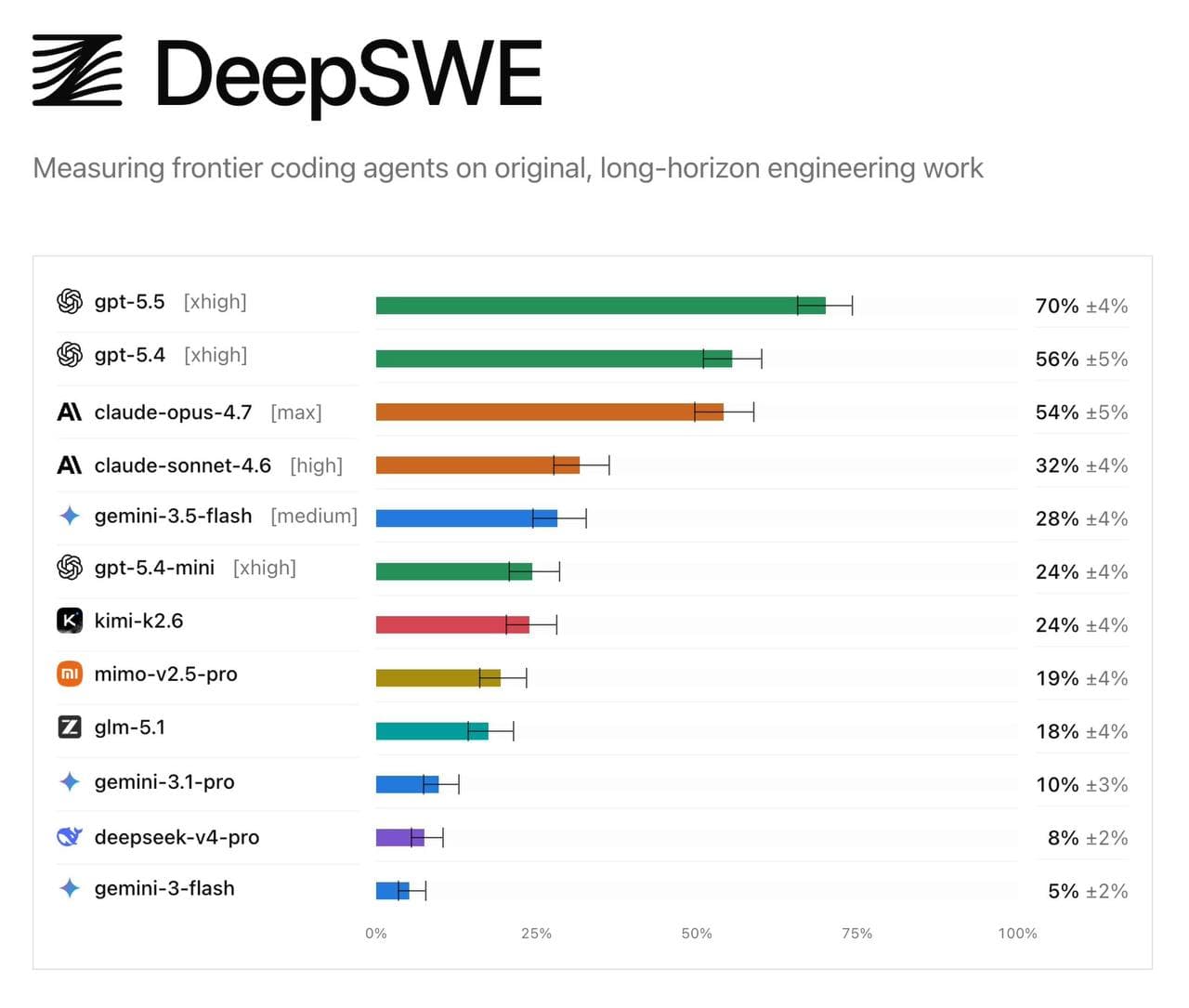
🤔 Смотря на результаты нового agentic coding бенчмарка DeepSWE становится понятно, что вся история вокруг Anthropic Mythos оказалась просто маркетингом.
Будь Mythos реально на порядок сильнее публичных моделей - Anthropic уже бы ее зарелизили, чтобы не отдавать рынок обратно OpenAI. GPT-5.5 выбивает 70%, GPT-5.4 - 56%, Claude Opus 4.7 на max - только 54%. То есть текущий флагман Anthropic проигрывает даже предыдущей итерации OpenAI, а Sonnet 4.6 проседает до 32%.
Coding - самый монетизируемый сегмент текущей AI-индустрии, и Anthropic тут теряет позиции. Держать "у нас внутри есть модель круче" имеет смысл только до тех пор, пока публичный конкурент не начинает реально съедать revenue. Существуй Mythos в той форме, в которой о ней рассказывали - ее бы уже показали.