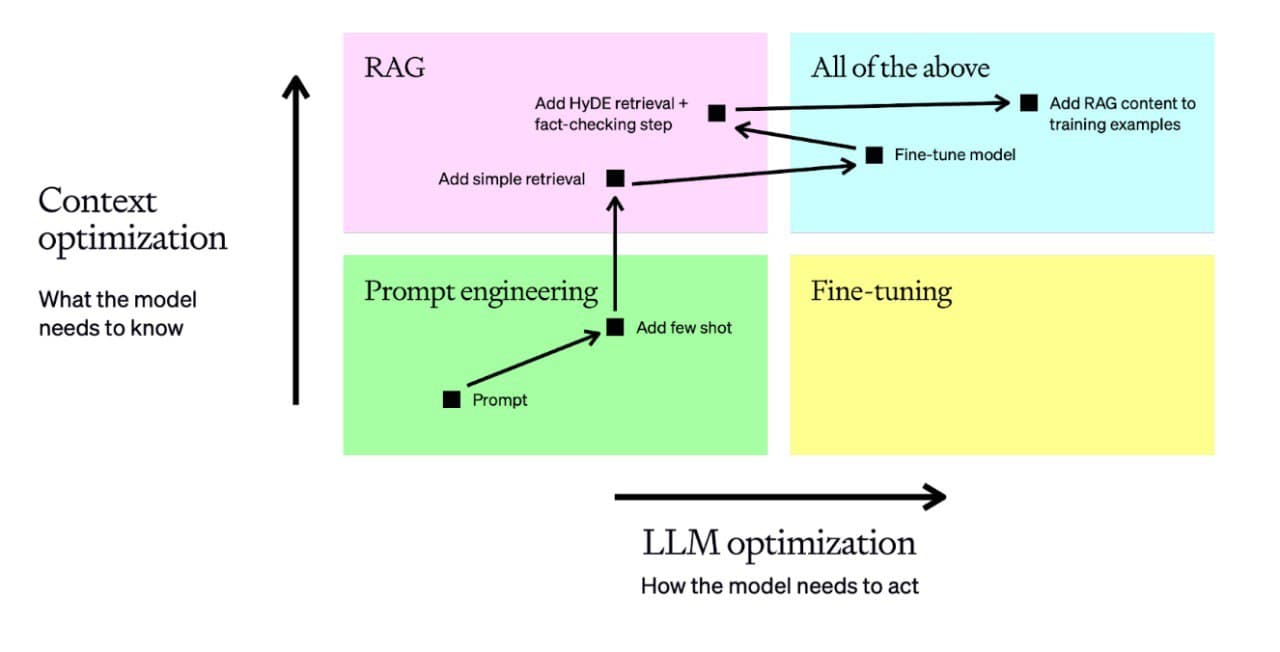
⚙️ Пошаговая оптимизация LLM от OpenAI
В свое время все бросились на finetuning, но быстро стало понятно, что это дорого и сложно, требуя качественного датасета и серьезных ресурсов. Finetuning — это крайняя мера, которая должна применяться только в случае необходимости. Именно поэтому так ценна поэтапная схема от OpenAI, которая позволяет достичь отличных результатов, продвигаясь от простых методов к более сложным:
1. Prompt Engineering: начальный этап — оптимизация запросов. Простой prompt с четкими инструкциями уже может улучшить результат.
2. Few-shot prompting: добавление нескольких примеров, чтобы повысить стабильность модели на схожих запросах.
3. Retrieval-Augmented Generation (RAG): если требуются специфические знания, добавляем динамическую подгрузку данных в prompt, что позволяет модели работать в нужном контексте.
4. Fine-tuning: завершающий шаг, когда необходима абсолютная точность и стабильность. Здесь уже создается специализированный датасет для обучения модели в реальных условиях.
Я бы еще добавил идею мультиагентности и одновременное использование моделей от разных производителей, но понятно, что не стоит ожидать этого в документации OpenAI
📝 Подробнее: https://platform.openai.com/docs/guides/optimizing-llm-accuracy