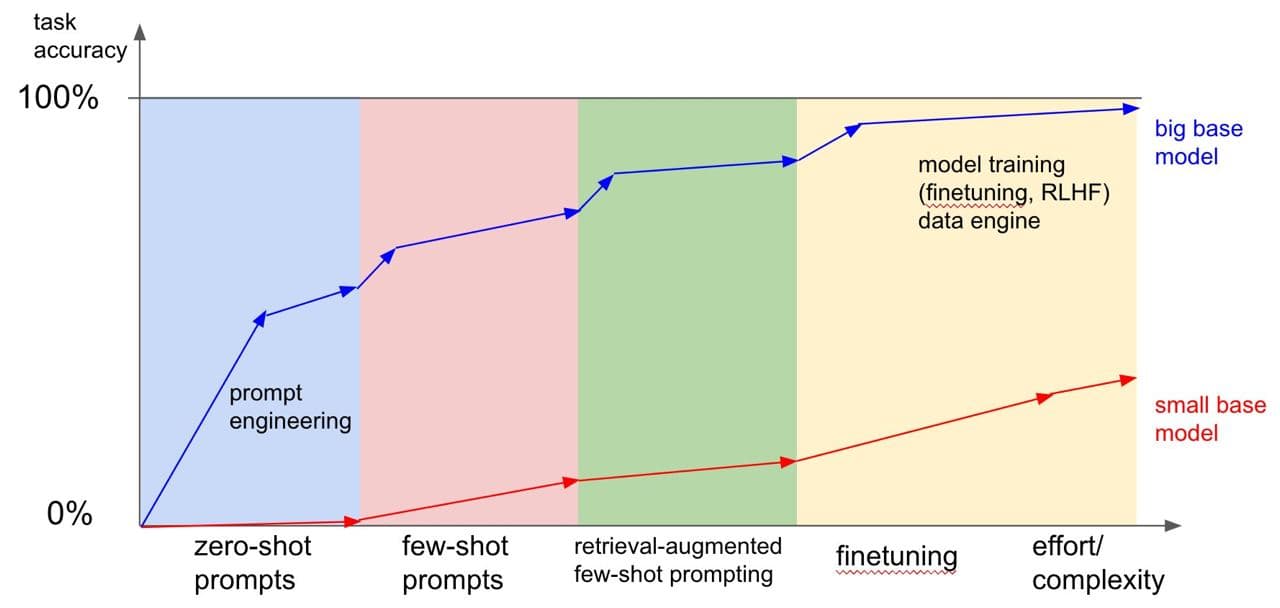
Andrej Karpathy's thoughts on comparing prompting (including embeddings) and finetuning for training LLMs (Large Language Models). Here’s what he says about different aspects of this process:
1. Zero-shot prompting (solving tasks without examples) - this is when the model solves a task without being provided examples of solutions, relying solely on its embeddings.
2. Few-shot prompting (solving tasks with a few examples) - this is when the model receives a small number of examples before solving the task, using its embeddings in conjunction with the provided examples.
3. Finetuning - the process of training the model based on specific examples and data to enhance its capabilities in solving tasks, adapting the embeddings and model parameters.
In the context of comparing prompting and finetuning, it becomes clear that achieving high accuracy in solving many tasks using only zero-shot or few-shot prompting is remarkable (providing examples as preprompts). However, to achieve the best results, finetuning is necessary, especially when it comes to specific, well-defined tasks, and a lot of training data is available.
It’s worth noting that small models, unlike large ones, are practically incapable of learning through zero-shot or few-shot prompting, but they can still be fine-tuned with careful selection of task complexity and solution methods.