Что лучше работает Prompting или Finetunning?
Размышления Andrej Karpathy на тему сравнения prompting (включая embeddings) и finetuning для обучения LLMs (Large Language Model). Вот что он говорит о разных моментах этого процесса:
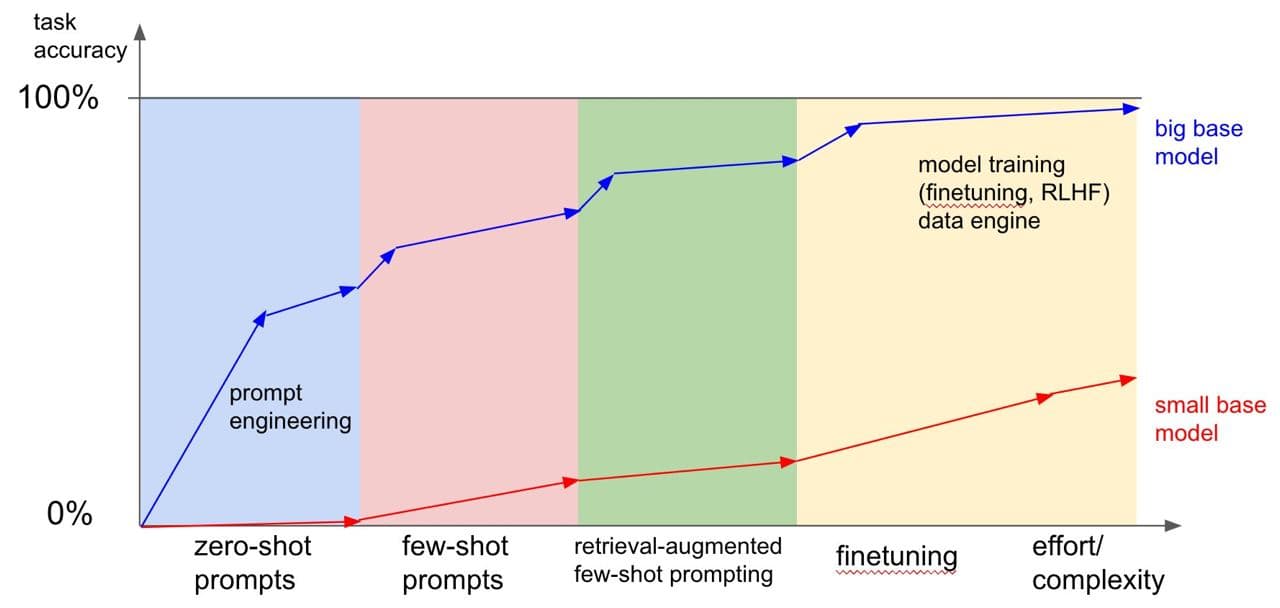
1. Zero-shot prompting (решение задач без примеров) - это когда модель решает задачу без предоставления примеров решений, опираясь исключительно на свои эмбеддинги.
2. Few-shot prompting (решение задач с несколькими примерами) - это когда модель получает небольшое количество примеров прежде, чем решать задачу, используя свои эмбеддинги в сочетании с предоставленными примерами.
3. Finetuning (дообучение) - процесс обучения модели на основе конкретных примеров и данных, чтобы улучшить ее способности в решении задач, адаптируя эмбеддинги и параметры модели.
В контексте сравнения prompting и finetuning становится ясно, что достижение высокой точности в решении множества задач, применяя только zero-shot или few-shot prompting, - это замечательно (подкладывать примеры как preprompt). Однако для достижения наилучших результатов необходимо применять finetuning, особенно когда речь идет о конкретных, четко определенных задачах, и доступно много данных для обучения.
Стоит учесть, что маленькие модели, в отличие от больших, практически не в состоянии обучаться при помощи zero-shot или few-shot prompting, но их все равно можно настроить с тщательным выбором сложности задачи и методов решения.